
Know how Git works: Behind the Scenes!🤯
What is Git and how it uses Data Structures and Algorithms in the backend that makes it the most in-demand skill of 2021


Git. A crisp three letter word; without which one cannot imagine a day in Software Development World. Right from the discussing and working on issues in the development stage to deployment of the application in production, and almost all the modern tools and technologies that are being used and developed; are indebted with the functionalities and flexibility that Git provides.
In this tutorial, we will understand some of the most important git commands, how they work Behind the Scenes and in what way the core concepts such as Graphs, Trees, Lists, Hashing etc. are practically employed in efficient working of Git.
So, what is Git?

Git is a distributed Version control system. A Version Control System is a tool or a software that is predominantly utilized to track, maintain and develop the codebase effectively. Specifically when working in a team, for instance say a Social media Company with 500+ developers coding alongside with you. Git helps everyone to collaborate and offers wide range of functionalities as under:
Track changes in the code base. See what changes your colleagues/employees are making and review them.
Create branches of a Project. Suppose you are working on ‘Story’ feature and your colleague is looking into ‘Security’ section, you both can work separately on a different branch and merge it later.
Easy experimentation and feature-based workflow.
Can Revert the changes. Yes, you heard it right. If you have made some mistake or error, you can clock back to your previous ’n’ changes!
Role-based approach. Not everyone must have rights to merge the code to the working application. Thus, by role-based approach it is well-managed.
Having said this, we now have pretty much a rough idea about what is Git and where it is being used. Now, it’s time to explore its fundamental concepts and working.
0. Git is a Graph
Many times one might have heard junior devs complaining about they being asked Data Structures and Algorithms in coding interviews, if don’t have to use them in real world. But, the underlying working of all tools and technologies involves implementation of efficient Algorithms and Data Structures. Hence, a clear understanding of these core concepts is utmost important.
Git is a Graph data structure. It is made up of nodes(objects) and pointers. There might be frequent changes happening in the project. For that, Git keeps a track of all the changes and files by storing it in graph form. At the core of Git, it is a repository and stores data as key-value entirely in the .git directory of your project root. Git repository consists of various entities. Few important ones are listed as below:
Blobs, that are used to store files in binary form as bytes.
Tree Objects, that points to Blobs and other tree objects.
Commit Objects, that contains meta data about the project and points to single tree object.
1. Initialize a Git Repository
Let us delve into the inner mechanism of Git and understand the commands along the way. The initial Folder Structure of our project is as below:
example
└── data
└── name.txt
In our project folder example, we want to incorporate Git functionalities. First, we initialize a Git Repository there in order to keep track and store all our work. It can be executed by git init command in command prompt.
~/example $ git init
Outputs: Initialized empty Git repository
Since the Git is initialized now, .git repository can be seen in example.
example
├── data
| └── name.txt
└── .git
├── objects
etc...
2. Add files to the Repository
Currently, though our folder has name.txtfile; but the git repository is still empty. To add it to the repository, we use git add path/filename command.
Add a new file to Git
~/example $ git add data/name.txt
By running the above command, following things happen:
A blob object is created that contains the contents the file added. Interesting to note that it uses Hashing Technique to store file names. Say, the content in ‘name.txt’ is the ‘harry’. The Hashing Algorithm converts the string
harryto2e65Then, the first two characters of the hashed value are used as the name of the directory(here, data) inside the objects database in.gitand the rest part of the hashed value is used to name the blob file(here, name.txt). In this way Git saves the content as blobs in objects directory. Also, the content inside thename.txtis hashed.It adds the file to the index. Note that, index is a list that contains every file that Git is tracking. It is stored in
.git/index. Each entry in theindexfile stores the file to be tracked and the corresponding hash in encoded form. Why it does this? We will see this in a second.
Let’s add another file named age.txt in the working copy. Also, putting age.txtfile to Git as well.
Re-add a file to a repository
~/example $ git add data
By executing the above command, we essentially add everything that is in data to Git. Since, the name.txt already exists in Git, it will only add age.txt to it and won’t do redundant processing. This is again, done by the graph difference computing algorithms running in backend.
The updated Folder Structure is as below:
example
├── data
| └── name.txt (content='harry')
| └── age.txt (content='20')
└── .git
├── objects
| └── 2e
| └── 65 (content= xK??0R0dH)
| └── 74 (content= xK??4567A)
├── index
└── ?H?u.data/name.txtd (decoded as: data/name.txt 2e65)
└── ?H?u.data/age.txtd (decoded as: data/age.txt 2e74)
(Please note that the hashes used here are for demonstration purpose only. In reality, the hashes are pretty long).
We can see that the age.txt is added to objectsas well as index file. Now, Harry is 21 years old. So we update contents in age.txt file. So, the working copy is changed.
By running git add command, it will reflect the changes in the working copy to the repository. Also, a log of the previous changes in the codebase is maintained. Here comes the role of index. The index points to the latest change happened in the repository. So, it will naturally point to the newly created blob object that was created after the change in age.txt
It is essential to note that the blob object that was pointed previously is not deleted. Just the index doesn’t point it now. So, whenever we want to revert the changes, the index file just has to point to older blobs.
Quite Simple, yet a smart way. Isn’t it?
3. Commit the changes
You must have used Google Docs. Once you are done with the work or want to take a break, you make sure to SAVE your work in Google Docs. Similarly, when Programmers complete their task or want to take a weekend off, they COMMIT the code to their Git repository.
To commit the changes to your git repository run-
~/example $ git commit -m 'initial commit'
Outputs: [master (root-commit) 774b] 'initial commit'
Here, the -m stands for ‘message’. The commit message we put up is ‘initial commit’, since it was our first commit. It is considered a good practice to write meaningful commit messages so that code and changes are easily readable and tracked for debugging or reviewing.
What happens when the command is run?
The commit command occurs in three steps. Lets understand each step in brief.
1. Tree Graph Object
A Tree Graph object gets created first on commit. It is composed of two types of objects: blob objects and tree objects. The Blobs contain the data that is added by the git add command. While the other tree objects are actually those relating to the other commits(as by commit command, tree object is created).
This is the first commit of the project. So, it will have only blob objects. Like we saw that blob objects are stored as hash values, tree objects also have a hash value assigned for reference.
2. Create a commit Object
After the creation of the Tree Graph, Git creates a Commit Object that points to the tree object. The Commit Object primarily stores the commit message in it and thus it is a compulsory parameter in the command. Also, it includes additional information such as author name, email, etc.
3. Point the current branch at the new commit
A branch is nothing but an independent copy of the codebase for a developer to work remotely and make changes in it. Since, Git is a distributed version control system, and so multiple creation of branches and development is supported.
But how do we know what is the current branch? That information is stored inside.git/HEAD In this file, there are various branch references saved. Whenever commit is made, Git searches through this file to find the current branch(where HEAD points to).
In our case, there are no branches created. By default, the HEAD points to master branch. The Git graph can be represented as:
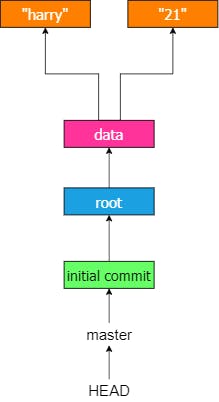
Lets make another commit
In this commit, we will change the contents in age.txt to 22 from 21. Then by git add we add this to our repository and sync it with the working copy. The older blob is dereferenced from index and the index now points to the new change. Now, its commit time!
git commit -m "change age"
You might have noticed that we wrote ‘change’ and not ‘changed’. Good Git commit messages are imperative in nature. Read more about commit messages here.
After this commit, the Git graph is updated as below:
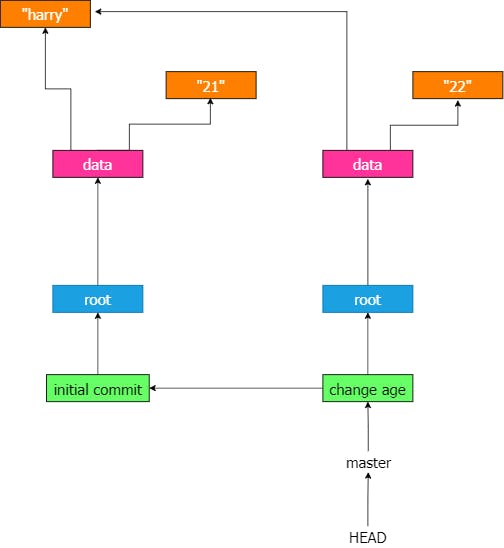
It can be observed that master now points to the new commit object and that object points to the older one. Essentially, only the difference between two commits is taken into consideration. These graph properties significantly reduce time complexity and makes Git super fast.
Conclusion
In this article, we understood how various Data Structures and Algorithms are used Behind the Scenes in Git. Hoping that this article might have helped you to grasp the working and capabilities more clearly. No matter you are a fresher or a sophomore in college, or appearing for placements later this year, or an open source enthusiast, or even an experienced developer, Git is important. Regardless of your interests and expertise in Machine Learning, Web Development, Cloud or Systems Design; Git is a must-know technology to master in your 2021 skillset list.
Further Reading: Refer the official Git book and its github repository if you want to explore Git functionalities in more detail.